Scaling, Accuracy Example¶
In this notebook, speed comparisons between the BAPE algorithm and the “brute force” method of just using your forward model for Bayesian parameter inference using MCMC (see https://github.com/dfm/emcee for our MCMC algorithm). We run the BAPE algorithm on the Wang & Li (2017) Rosenbrock function example and consider cases where instead of the \({\sim}10\mu\)s runtime of the analytic Rosenbrock function, it took anywhere from \(10^{-3}\)s to \(10^{4}\)s. This exercise allows to
us crudely estimate how slow a forward model must be before using approximate methods such as approxposterior is warranted.
[1]:
%matplotlib inline
from approxposterior import approx, likelihood as lh, gpUtils as gpu
import george
import corner
import emcee
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams.update({'font.size': 18})
Initialize and run the example.
[2]:
# Define algorithm parameters
m0 = 50 # Initial size of training set
m = 20 # Number of new points to find each iteration
nmax = 3 # Maximum number of iterations
bounds = [(-5,5), (-5,5)] # Prior bounds
algorithm = "bape" # Use the Kandasamy et al. (2015) formalism
# emcee MCMC parameters
samplerKwargs = {"nwalkers" : 20} # emcee.EnsembleSampler parameters
mcmcKwargs = {"iterations" : int(1.0e4)} # emcee.EnsembleSampler.run_mcmc parameters
[3]:
# Sample initial conditions from the prior
theta = lh.rosenbrockSample(m0)
# Evaluate forward model log likelihood + lnprior for each theta
y = np.zeros(len(theta))
for ii in range(len(theta)):
y[ii] = lh.rosenbrockLnlike(theta[ii]) + lh.rosenbrockLnprior(theta[ii])
### Initialize GP ###
gp = gpu.defaultGP(theta, y)
[4]:
# Initialize object using the Wang & Li (2017) Rosenbrock function example
ap = approx.ApproxPosterior(theta=theta,
y=y,
gp=gp,
lnprior=lh.rosenbrockLnprior,
lnlike=lh.rosenbrockLnlike,
priorSample=lh.rosenbrockSample,
algorithm=algorithm,
bounds=bounds)
This time, turn on the timing option with timing=True in the run method.
Setting timing=True allows the code to profile how long various parts of the algorithm take to run. If timing=True, then the code keeps track of, for each iteration, how long it takes to find \(m\) new design points retrain the Gaussian Process, run the MCMC, fit the Gaussian Mixture Model approximation to the joint posterior distribution, and estimate the KL divergence between the current and previous joint posterior distributions.
[5]:
# Run!
ap.run(m=m, nmax=nmax, estBurnin=True, mcmcKwargs=mcmcKwargs, cache=False,
samplerKwargs=samplerKwargs, verbose=False, timing=True)
Estimate Time Scaling as a Function of Forward Model Time
Now, imagine that our forward model takes anywhere \(10^{-5}\)s to \(10^{4}\)s for one evaluation. In the “brute force” method, for each iteration for each walker, the MCMC algorithm runs the forward model, typically resulting in \(>10^5\) forward model evaluations! Obviously for slow forward models, this readily becomes computationaly intractible. Here, we show how the “brute force” method scales compared to approxposterior’. In this section, we take care to accurately
time all facets of the algorithm while factoring in different forward model evaluation times.
[6]:
# Create synthetic forward model times in seconds
ns = np.logspace(-5,4,10)
# Number of evluations in the MCMC chain
niters = mcmcKwargs["iterations"]
# "Brute force" times are the number of evaluations times the forward model evaluation time
bruteTimes = ns*niters
[7]:
# Compute GP training time factoring in synthetic forward model run times
gpTimes = np.zeros(len(ns))
for ii in range(len(ns)):
# The algorithm initializes with m0 forward model evaluations
gpTimes[ii] = m0*ns[ii]
# Loop over iterations
for jj in range(len(ap.trainingTime)):
# Add time of running forward model to get m new points and training GP, running mcmc,
# change in KL divergence, and GMM estimation times
gpTimes[ii] += m*ns[ii] + ap.trainingTime[jj] + ap.mcmcTime[jj]
Plot the scalings to see where both methods are faster!
Below, we plot the total time it takes for the full Bayesian parameter inference (y axis) as a function of forward model evaluation time (x axis).
[8]:
fig, ax = plt.subplots(figsize=(9,8))
ax.plot(ns, bruteTimes, "o-", lw=2.5, label="MCMC")
ax.plot(ns, gpTimes, "o-", lw=2.5, label="approxposterior")
# Reference year, month, week, day, hour timescales
ax.axhline((365*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax.axhline((30*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax.axhline((7*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax.axhline((24*60*60), lw=2, ls="--", color="k", zorder=0)
ax.axhline((60*60), lw=2, ls="--", color="k", zorder=0)
# One minute forward model reference
#ax.axvline(60, lw=2, ls=":", color="k", zorder=3)
ax.text(1.0e-5, 4.0e7, "Year")
ax.text(1.0e-5, 3.5e6, "Month")
ax.text(1.0e-5, 7.0e5, "Week")
ax.text(1.0e-5, 1.2e5, "Day")
ax.text(1.0e-5, 4.4e3, "Hour")
ax.set_ylabel("Total Computational Time [s]")
ax.set_xlabel("Time per Forward Model Evaluation [s]")
ax.set_xscale("log")
ax.set_yscale("log")
ax.legend(loc="lower right")
# fig.savefig("scaling.pdf", bbox_inches="tight")
[8]:
<matplotlib.legend.Legend at 0x1a1c31e610>
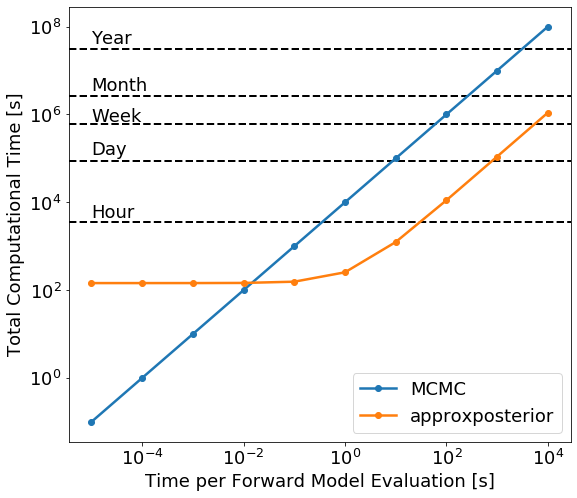
There are two clear regimes in this figure. For very fast forward models, \(t<10^{-2}\)s per evaluation, it’s slower to train the Gaussian process then actually run the MCMC using the true forward model, so in this case it’s not worth using approximate methods. For slow forward models, \(t>10\)s per model evaluation, most of the time is spent running the forward model to give training points to the Gaussian process, so the actual MCMC inference is relatively computationally cheap.
The turnover when it’s faster to use approxposterior occurs once the forward model takes \({\sim}1-10\)s to run. Once the forward model takes a few minutes to run, however, the approximate method completes in of order hours while the brute force method can take up to a month – a massive speed-up!
Strictly speaking, this scaling plot applies to the Rosenbrock function example from Wang & Li (2017). Scaling plots like the one above depend on how many MCMC iterations you use, the MCMC algorithm, how many samples the GP is trained on, and probably the GP kernel. For example, longer MCMCs have a raised floor for the flat region of the GP approximation curve and dictate when the turnover occurs.
For slow forward models, the approximate methods are clearly faster. But how accurate are the results?
Above, we used the exact algorithm parameters Wang & Li (2017) used for their Rosenbrock function example. In the True_Rosenbrock_Posterior example notebook, we ran an MCMC inference using the true Rosenbrock function likelihood and algorithm parameters from Wang & Li (2017) to derive the “true” joint posterior distribution. Below, we visually and numerically compare the approximation to the joint posterior distribution derived above with true distribution to see how accurate the approximate method is.
[9]:
# Load in the true chains from the True_Rosenbrock_Posterior example notebook
trueMcmc = np.load("trueRosenbrock.npz")
trueFlatchain = trueMcmc["flatchain"]
trueIburn = trueMcmc["iburn"]
[10]:
fig, ax = plt.subplots(figsize=(7,6))
bins = 20
# Plot GP approximation to the joint distribution
samples = ap.sampler.get_chain(discard=ap.iburns[-1], flat=True, thin=ap.ithins[-1])
corner.hist2d(samples[:,0], samples[:,-1],
bins=bins, ax=ax, color="C3", plot_density=False, plot_contours=True, plot_datapoints=False,
label="GP Approximation")
# Plot the true joint distribution
corner.hist2d(trueFlatchain[trueIburn:,0], trueFlatchain[trueIburn:,1], bins=bins,
ax=ax, color="black", plot_density=True, plot_contours=False, plot_datapoints=False)
# Formating
ax.text(-2.2, -1.5, "Truth", color="black")
ax.text(-2.2, -2, "approxposterior", color="C3")
ax.set_xlabel("x0")
ax.set_ylabel("x1")
fig.savefig("accuracy.pdf", bbox_inches="tight")
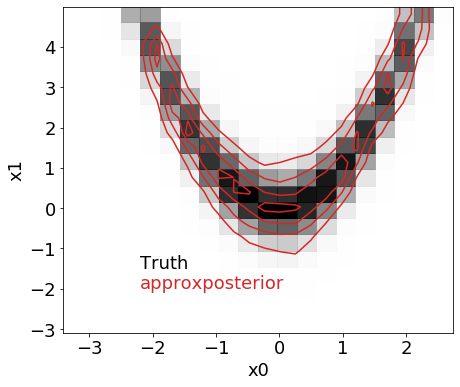
The true and approximate distributions look nearly identical! How do the 0.16, 0.5, 0.84 quantiles compare for the 2 parameters, x0 and x1?
[11]:
approxX0 = np.percentile(samples[:,0],[0.16, 0.5, 0.84])
approxX1 = np.percentile(samples[:,1],[0.16, 0.5, 0.84])
trueX0 = np.percentile(trueFlatchain[trueIburn:,0],[0.16, 0.5, 0.84])
trueX1 = np.percentile(trueFlatchain[trueIburn:,1],[0.16, 0.5, 0.84])
[12]:
print("x0")
print("True\t", trueX0)
print("Approx\t", approxX0)
print("")
print("x1")
print("True\t", trueX1)
print("Approx\t", approxX1)
x0
True [-2.4136162 -2.32461971 -2.27654002]
Approx [-2.17418768 -2.11799219 -2.08216416]
x1
True [-1.70102134 -1.40117241 -1.25195281]
Approx [-1.64048781 -1.3753925 -1.22776931]
The answers are consistent - great!
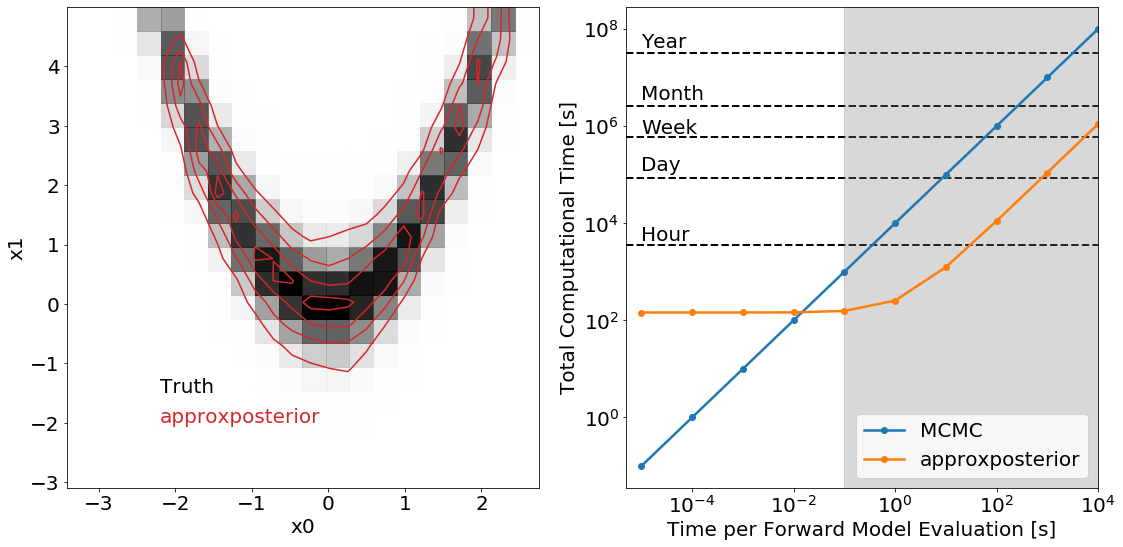
Plot them together
Good for posters and stuff.
[13]:
mpl.rcParams.update({'font.size': 20})
fig, ax = plt.subplots(ncols=2, figsize=(16,8))
# Left: Accuracy
bins = 20
# Plot GP approximation to the joint distribution
corner.hist2d(samples[:,0], samples[:,1],
bins=bins, ax=ax[0], color="C3", plot_density=False, plot_contours=True, plot_datapoints=False,
label="GP Approximation")
# Plot the true joint distribution
corner.hist2d(trueFlatchain[trueIburn:,0], trueFlatchain[trueIburn:,1], bins=bins,
ax=ax[0], color="black", plot_density=True, plot_contours=False, plot_datapoints=False)
# Formating
ax[0].text(-2.2, -1.5, "Truth", color="black")
ax[0].text(-2.2, -2, "approxposterior", color="C3")
ax[0].set_xlabel("x0")
ax[0].set_ylabel("x1")
# Right: Scaling
ax[1].plot(ns, bruteTimes, "o-", lw=2.5, label="MCMC")
ax[1].plot(ns, gpTimes, "o-", lw=2.5, label="approxposterior")
# Reference year, month, week, day, hour timescales
ax[1].axhline((365*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax[1].axhline((30*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax[1].axhline((7*24*60*60), lw=2, ls="--", color="k", zorder=0)
ax[1].axhline((24*60*60), lw=2, ls="--", color="k", zorder=0)
ax[1].axhline((60*60), lw=2, ls="--", color="k", zorder=0)
# Shade region or typical vplanet runtimes
ax[1].axvspan(0.1, 1.0e4, color='grey', alpha=0.3)
ax[1].text(1.0e-5, 4.0e7, "Year")
ax[1].text(1.0e-5, 3.5e6, "Month")
ax[1].text(1.0e-5, 7.0e5, "Week")
ax[1].text(1.0e-5, 1.2e5, "Day")
ax[1].text(1.0e-5, 4.4e3, "Hour")
ax[1].set_ylabel("Total Computational Time [s]")
ax[1].set_xlabel("Time per Forward Model Evaluation [s]")
ax[1].set_xlim(5.0e-6,1.0e4)
ax[1].set_xscale("log")
ax[1].set_yscale("log")
ax[1].legend(loc="lower right")
fig.tight_layout()
fig.savefig("acc_scal_shaded.pdf", bbox_inches="tight")
[ ]: